LLMs.txthas gained significant attention in the AEO (Answer Engine Optimization) space since itsfirst proposal in 2024. At a surface level, it appears similar to robots.txt, suggesting a simple way to guide how AI systems interpret website content. In reality, its role, adoption, and technical impact are far less direct.
A 2024 survey by Ziff Davisfound that most SEO professionals were aware of LLMs.txt, but few understood how it actually works. That gap has led to widespread assumptions that are now influencing content and technical decisions without a clear factual basis.
This blog explains whatLLMs.txtactually is, what it does not do, and the most common misconceptions shaping its adoption in AEO discussions.
How LLMs Select and Use Information from the Web?
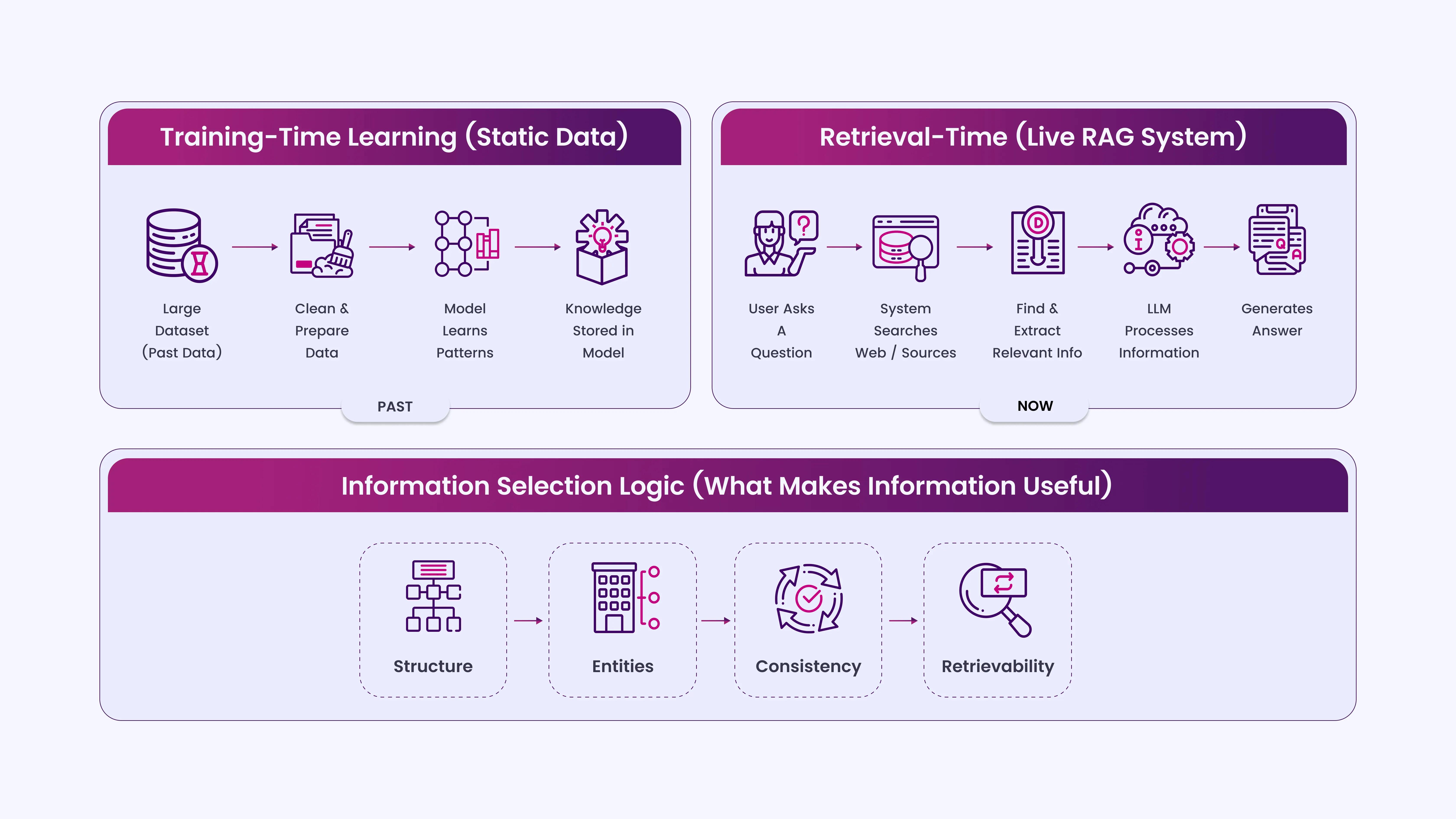
LLMsdon’t read or interpret websites the way traditional search engines do. They operate in two distinct ways:
- Training-time learning:Models learn patterns from large datasets collected earlier. This data is static at the time of training and is not influenced by files like LLMs.txt.
- Retrieval-time answering (RAG systems):Some AI tools fetch live or indexed web content at query time. They then extract and summarize relevant passages.
Within this setup, content is selected based on:
- Clarity of structure (headings, sections, formatting)
- Entity recognition (brands, concepts, topics clearly defined)
- Content consistency across multiple sources
- Retrievability (how easily a passage can be extracted and summarized)
LLMs do not “follow instructions” from a single file. They prioritize patterns, structure, and repetition across trusted sources.
7 Common LLMs.txt Myths in AEO Workflows
To understand where the confusion comes from, it helps to separate what LLMs.txt is claimed to do from how AI systems actually behave.
Myth 1: LLMs.txt is an Official Standard like robots.txt
robots.txt is governed byRFC 9309, an accepted Internet standard with decades of documented crawler behavior. LLMs.txt has no such backing.
LLMs.txt was proposed byJeremy Howard in September 2024as a convention for making website content more AI-readable. It has not been adopted by any standards body, not the W3C, not the IETF, not any major AI lab. There is no formal specification, no compliance requirement, and no governing body enforcing it.
Several companies have adopted it voluntarily, but adoption does not equal standardization. A file placed on your server with the name llms.txt has no guaranteed effect unless a specific AI system is explicitly built to read and act on it.
Myth 2: Adding LLMs.txt Will Get Your Content Cited by AI Models
This is the most common misconception. People assume that if they add an LLMs.txt file, AI tools likePerplexity,ChatGPT, or Gemini will start citing their content more often. There is no evidence that these systems work this way.
Large language models are trained on a large corpus of data collected over time. Training pipelines may or may not honor any file-level instructions present on a website, and that decision is entirely at the model developer’s discretion. LLMs.txt does not function as a signal within the training pipeline in any verified, documented way.
Retrieval-augmented generation (RAG) systems that browse the web in real time, like Perplexity or Bing Chat, operate through their own crawlers and indexing logic. Whether they read LLMs.txt is a product decision, not something site owners can assume.
Myth 3: LLMs.txt Works the Same Way as robots.txt
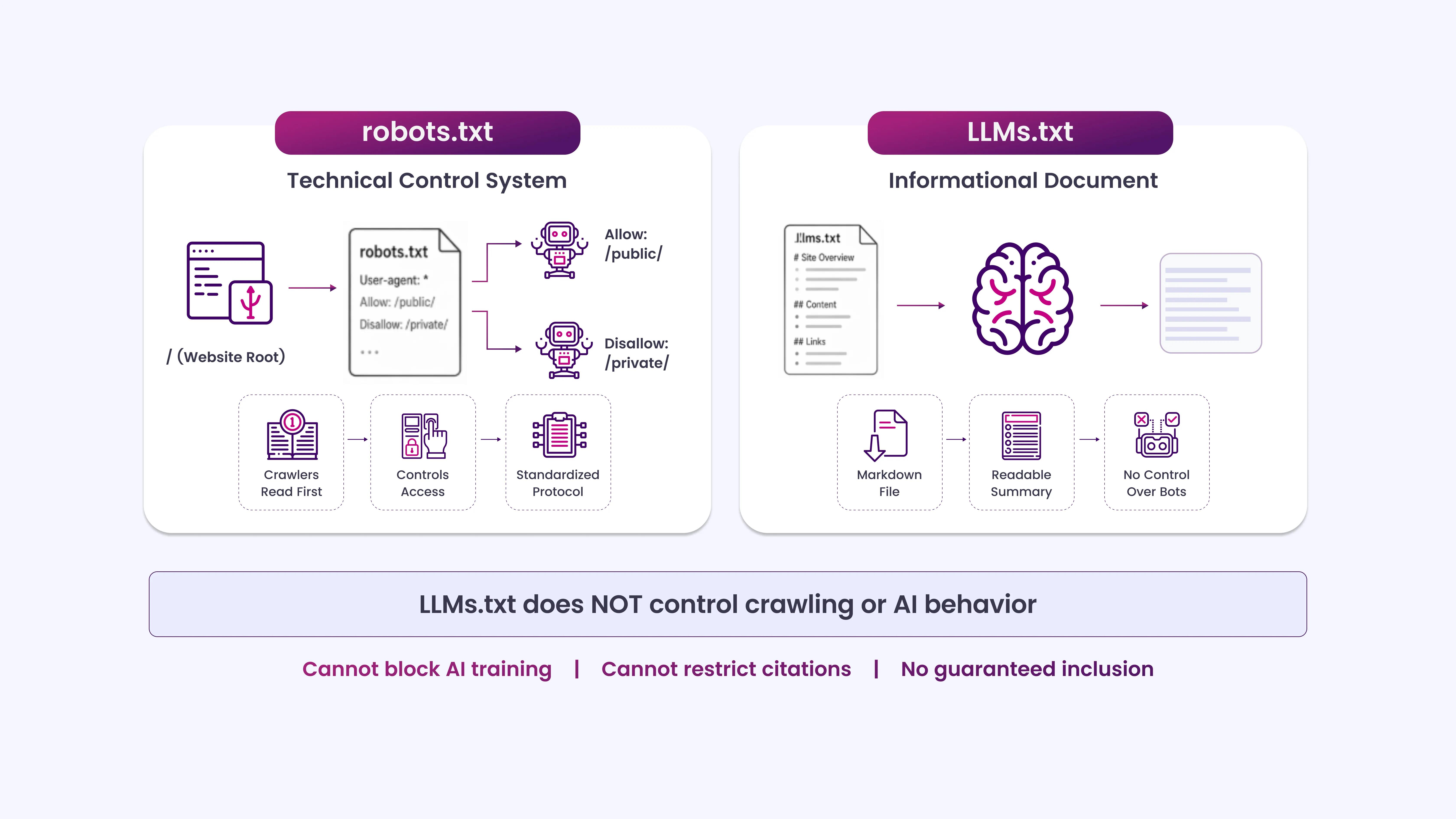
robots.txt communicates with crawlers at the HTTP request level. Bots read the file before crawling and adjust their behavior accordingly. The protocol has been tested and standardized for over 30 years.
LLMs.txt works nothing like this. It is a Markdown file, not a machine-readable protocol. It is meant to summarize your site’s content in a format that AI systems can process more easily, essentially a structured index for humans and machines to read. It does not block, allow, or redirect AI behavior the way robots.txt directs crawlers.
Treating LLMs.txt as a “robots.txt for AI” leads to incorrect expectations. You cannot use it to block AI training, prevent citation, or guarantee inclusion.
Myth 4: LLMs.txt Can Prevent AI Models from Training on Your Content
This is a belief with real stakes and real disappointment attached. Some site owners have added LLMs.txt, hoping it would prevent AI companies from training on their data. It does not do that.
Preventing AI training requires either a legal agreement, an active terms-of-service clause, or specific technical measures that AI crawlers respect, such as the AI-Data-Optout header or specific entries in robots.txt that some AI labs (like Google DeepMind and OpenAI) have said they will honor.
LLMs.txt makes no such promises and carries no enforcement mechanism. Adding it as a data opt-out tool is entirely a misunderstanding of its purpose.
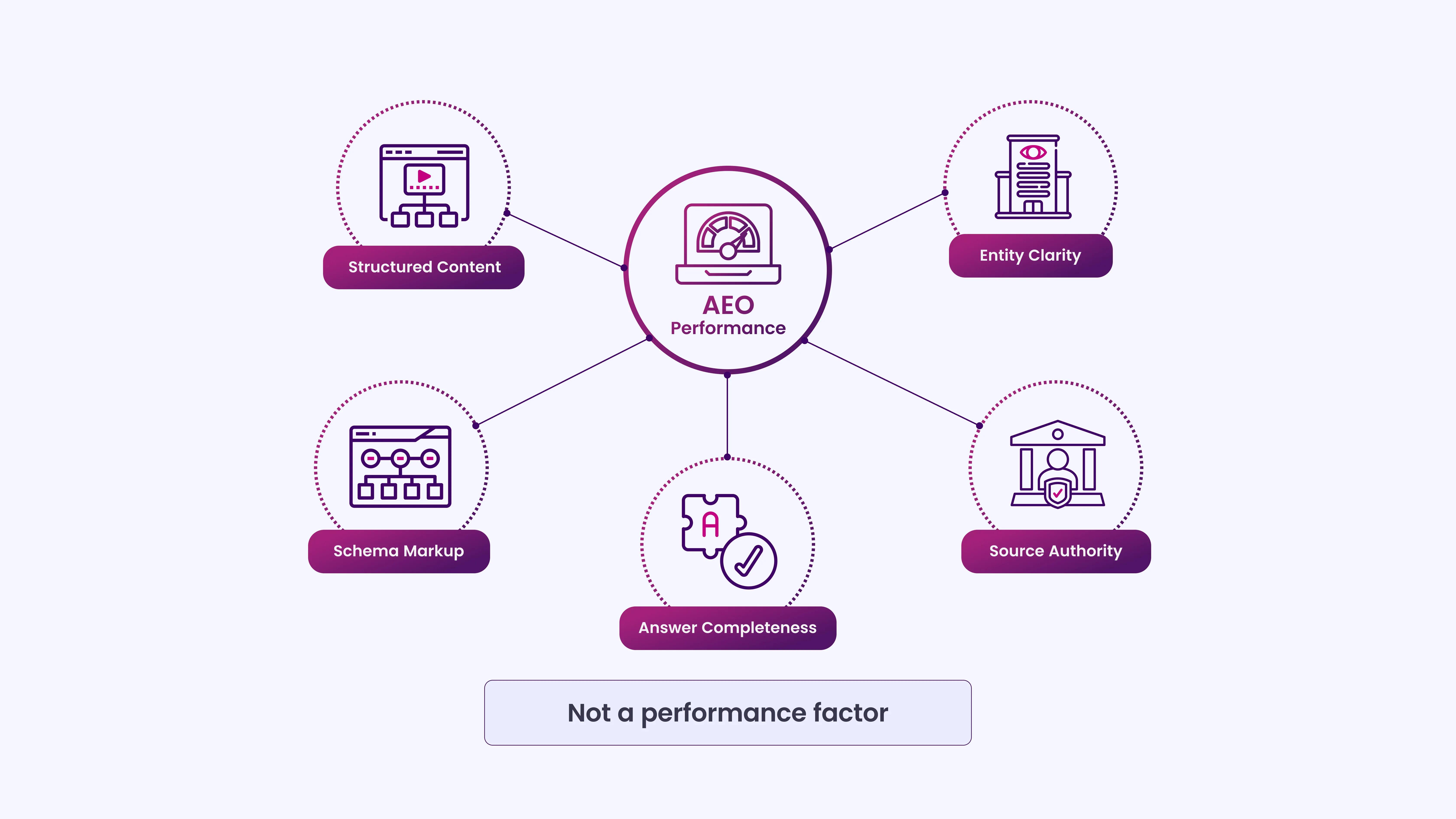
Myth 5: A Well-Formatted LLMs.txt File Improves Your AEO Rankings
There is no ranking system in AEO that reads LLMs.txt. AI answer engines generate responses based on a combination of model training, retrieval algorithms, and quality signals, not on a Markdown file hosted at the root of your domain.
The factors that actually improve AEO performance are well-documented:
- Structured content:Clear headings, logical flow, and direct answers to specific questions.
- Entity clarity:Consistent use of your brand name, author names, and topic associations.
- Schema markup:Structured data that machines can parse without guesswork.
- Source authority:Backlinks, citations, and editorial signals that models use to assess credibility.
- Answer completeness:Content that fully addresses a question without requiring the reader to go elsewhere.
None of these is a file. LLMs.txt does not substitute for any of them.
Myth 6: All AI Systems Will Eventually Support LLMs.txt
This claim is speculative and often repeated as though it is a roadmap. The reality is that no major AI lab, OpenAI, Google, Anthropic, Meta, or Mistral, has publicly committed to honoring LLMs.txt as a standard.
Perplexity AI indicated in 2024 that it was exploring how to work with site-level AI instructions, but no formal support announcement has followed. Some smaller AI tools and research projects have adopted the format, but broad adoption by inference-time systems is neither guaranteed nor likely in the near term.
The trajectory of LLMs.txt depends entirely on whether large AI systems find it valuable, and that has not been decided.
Myth 7: LLMs.txt Replaces the Need for Good Content Structure
Some practitioners have started treating LLMs.txt as a shortcut, a way to tell AI what their site is about without investing in actual content quality. This is backward.
At its best, LLMs.txt is a content summary layer. It works only if the underlying content is well-organized, factually strong, and structured clearly enough to be worth summarizing. A poorly written, thin, or ambiguous site does not become AI-readable by adding a file at the root.
For AEO purposes, the following still matter more than any file-level declaration:
- Clear, question-based headings
- Concise, factually grounded answers
- Defined authorship and topical focus
- Structured data where applicable
- Content depth that matches the query intent
LLMs.txt is a wrapper, not a replacement.
Where LLMs.txt Fits in an AEO Strategy
LLMs.txt is a useful idea that has been over-interpreted by a content industry hungry for quick fixes. It is not an official standard, not a ranking signal, not a training opt-out mechanism, and not a substitute for content quality.
What it does offer, in narrow, specific contexts, is a cleaner way to present your site’s
structure to AI systems designed to read it. That is a reasonable, if modest, benefit.
For anyone working on AEO, the best investment remains the same: write clearly, structure logically, build authority through verifiable expertise, and make it easy for both humans and machines to understand what your content says. No file changes that equation.
Build AI-Ready Content Systems That Earn Authority with INSIDEA

Understanding what LLMs.txt does not do is only half the equation. The real advantage comes from building content that AI systems can reliably extract, interpret, and cite.
INSIDEAworks with teams to align their content strategy with how answer engines actually retrieve and surface information.
Here’s how we help:
- AEOContent Structuring:We restructure pages to ensure answers are clear, self-contained, and optimized for AI response extraction.
- Question-LedContentMapping:We identify high-intent, answer-driven queries and build content that directly addresses them.
- Entity & Authority Alignment:We strengthen how your brand, authorship, and topics are consistently represented across content.
- SERP & AI Placement Analysis:We track where your content appears in featured snippets, PAA boxes, and AI-generated answers.
- Content Gap & Opportunity Identification:We surface unanswered or only partially answered queries where your content can realistically gain visibility.
When content is built for clarity, structure, and retrieval, not shortcuts or file-based signals, it gets picked up where users are already getting answers.