Here’s one lil practice for you: Open ChatGPT and ask it to recommend the best project management software for a growing team. You’ll get a direct recommendation, not a list of links or search results.
Now repeat the same process for your own brand.
Open ChatGPT, Perplexity, Claude, and Gemini and run these prompts: “What do you know about [your brand name]?” and “What are the best [your category] tools for [your use case]?”
The output you get is closer to your real AI search presence than any traditional rank tracker report.
Traffic from ChatGPT, Gemini, Claude, Perplexity, and Grok grew 527% year over year, while traditional organic traffic increased by less than 4%. A large share of searches now ends without a click, as users get answers directly inside AI responses. If your brand is not included in those answers, it is not part of the consideration set.
This guide explains how to audit visibility across LLMs, document what appears, identify gaps, and track changes over time.
The Four Dimensions of LLM Brand Visibility
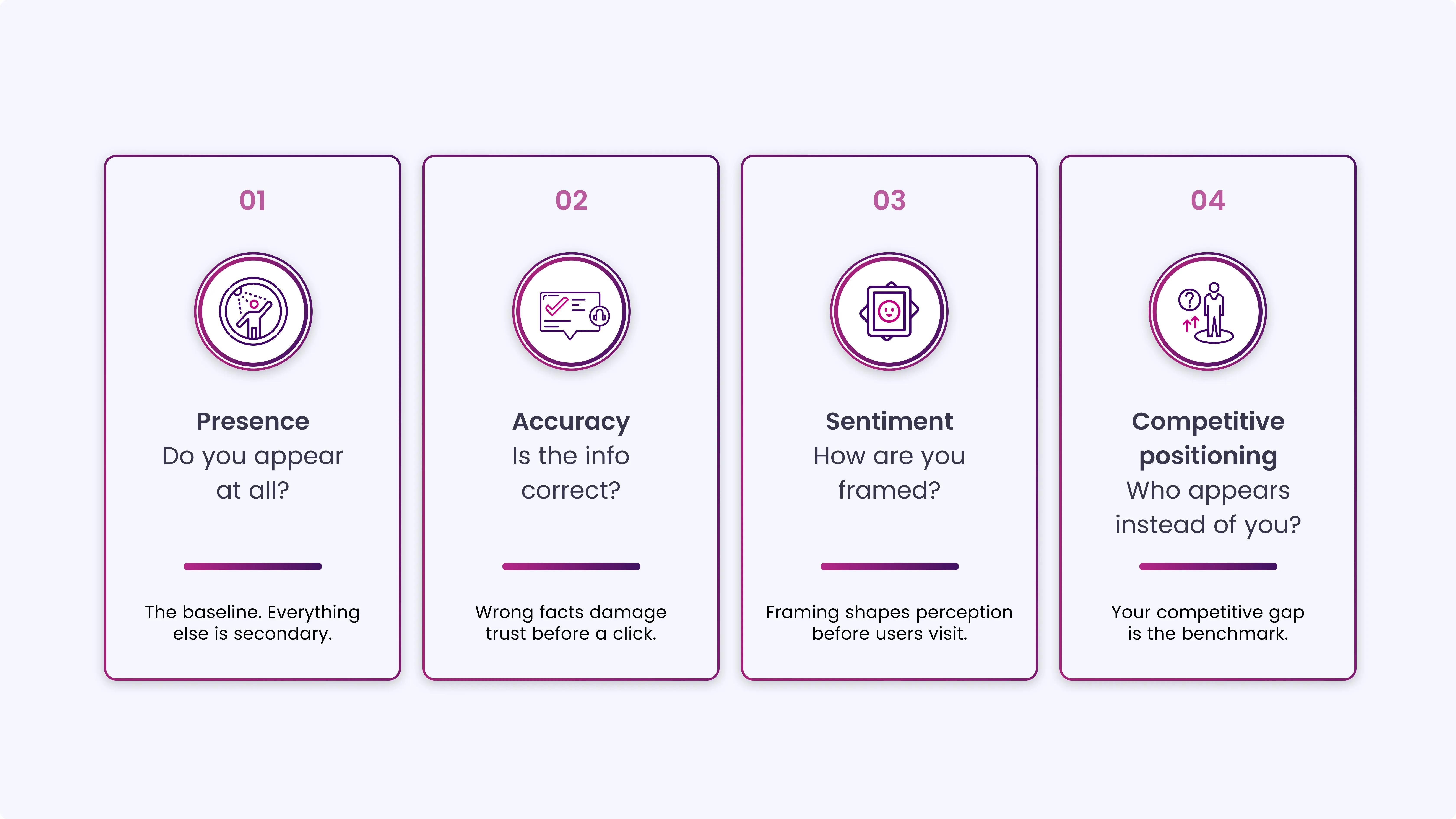
Before running any prompts, you need to know what you are measuring. An LLM brand audit has four distinct dimensions. Each one tells you something different.
- Presence: Does your brand appear at all when someone asks a relevant question? This is the baseline. If the answer is no, everything else is secondary
- Accuracy: When your brand does appear, is the information correct? Wrong founding year, outdated pricing, misattributed products, incorrect service descriptions, these all damage trust with users who act on what the AI says.
- Sentiment: How is your brand framed? Is it described as a reliable option, a budget alternative, an enterprise solution, or something else? The framing shapes perception before a user ever visits your site.
- Competitive Positioning: Who appears alongside you, or instead of you? Which competitors get cited more consistently? In which contexts does your brand lose to a competitor?
These four dimensions are your audit framework. Every prompt you run should be documented against all four.
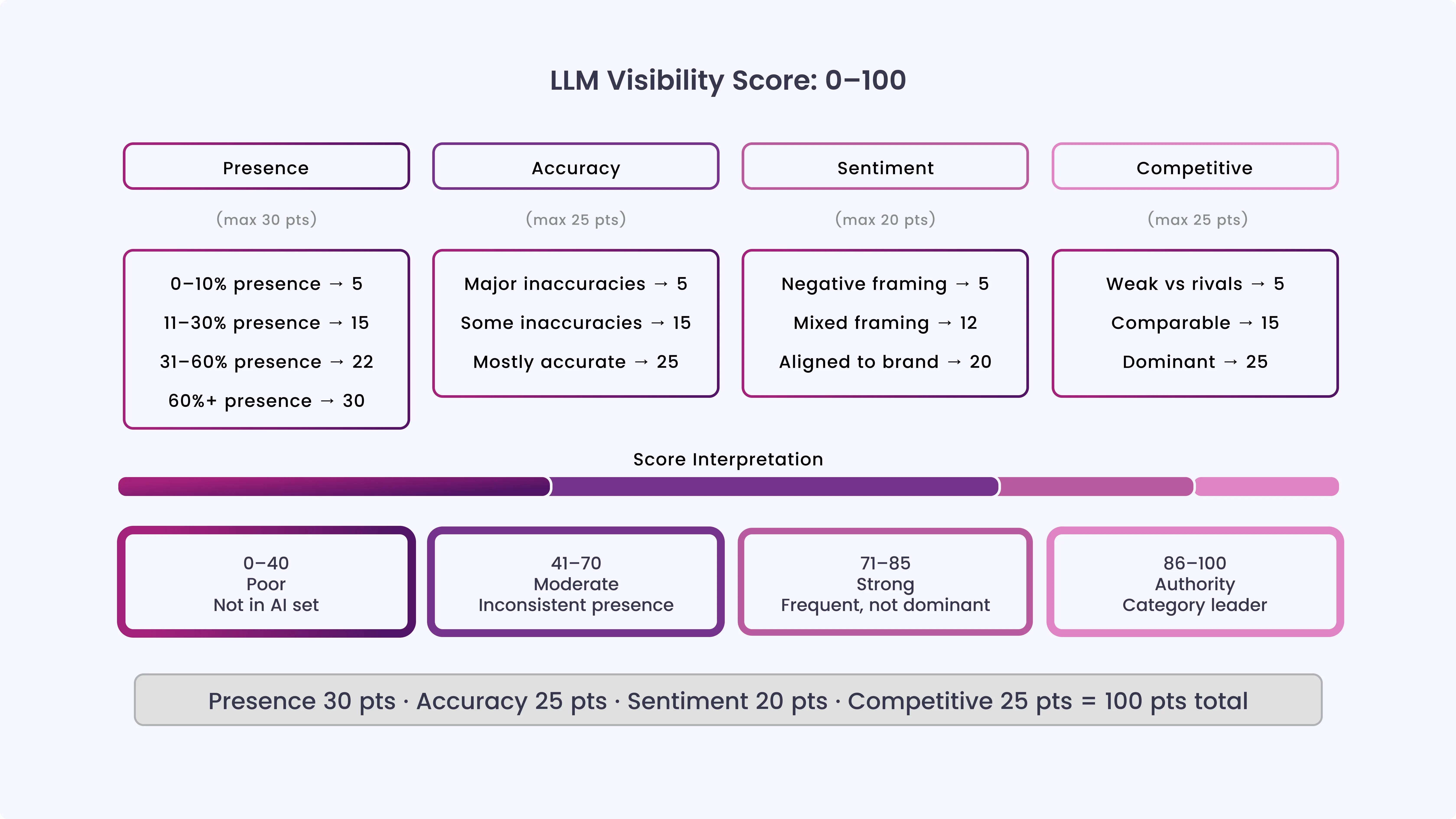
LLM Visibility Score (0–100 Framework)A simple score helps you see where your brand actually stands, rather than just guessing from individual results. It turns what LLMs say about your brand into metrics you can measure and track over time, covering presence, accuracy, sentiment, and competitors.
|
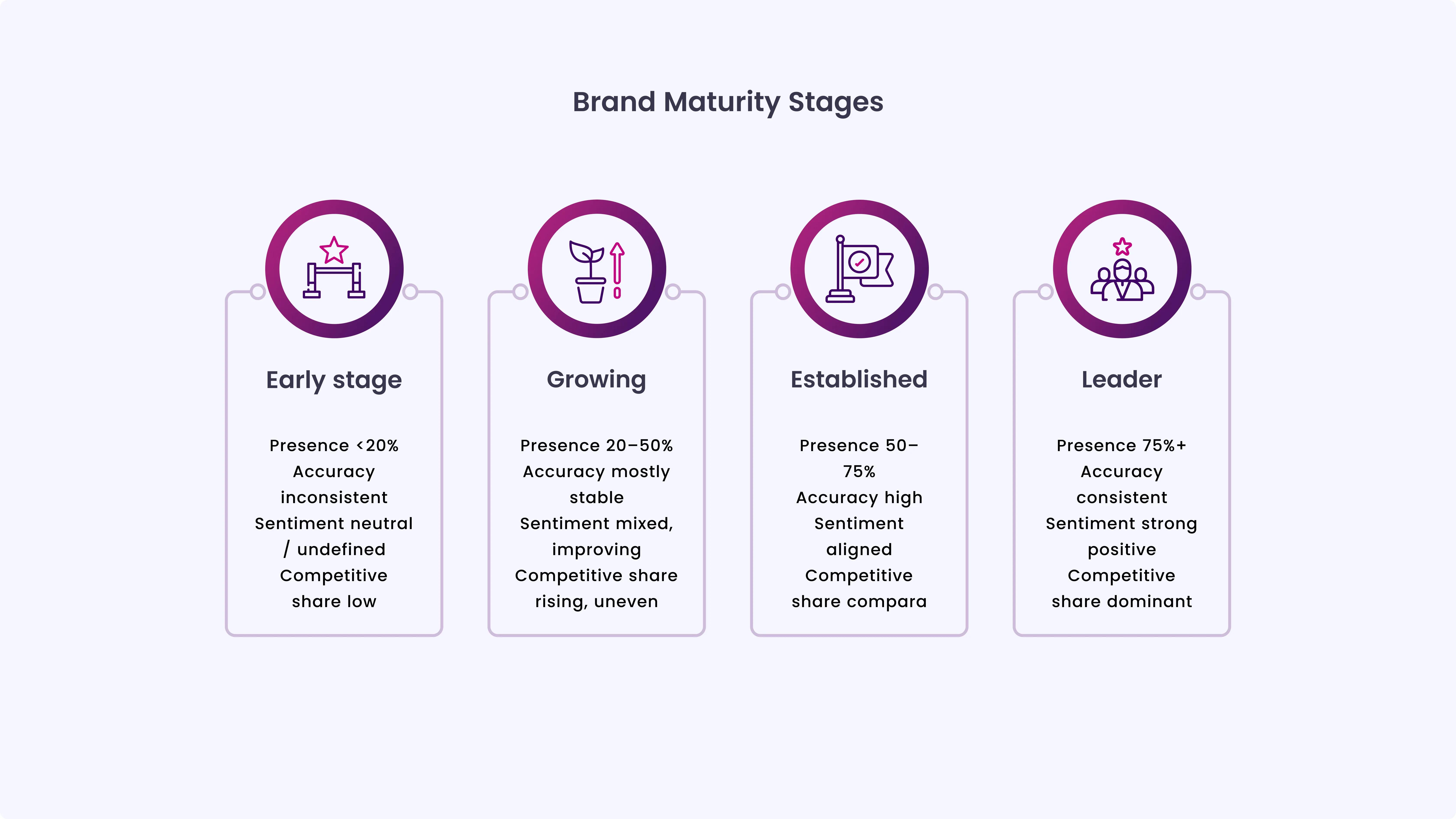
Use this maturity map to quickly benchmark your brand’s current LLM visibility before moving into the full audit process:
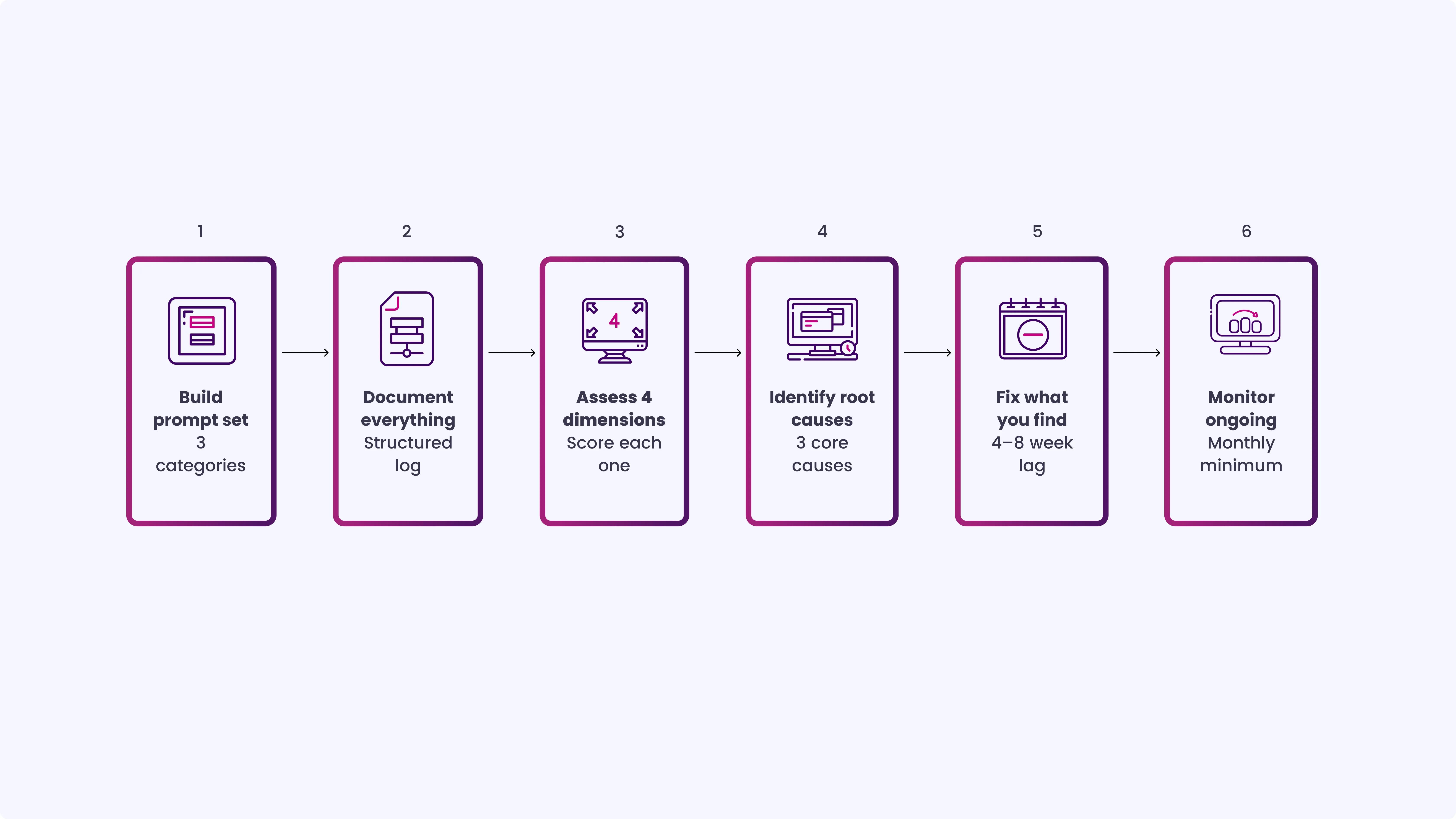
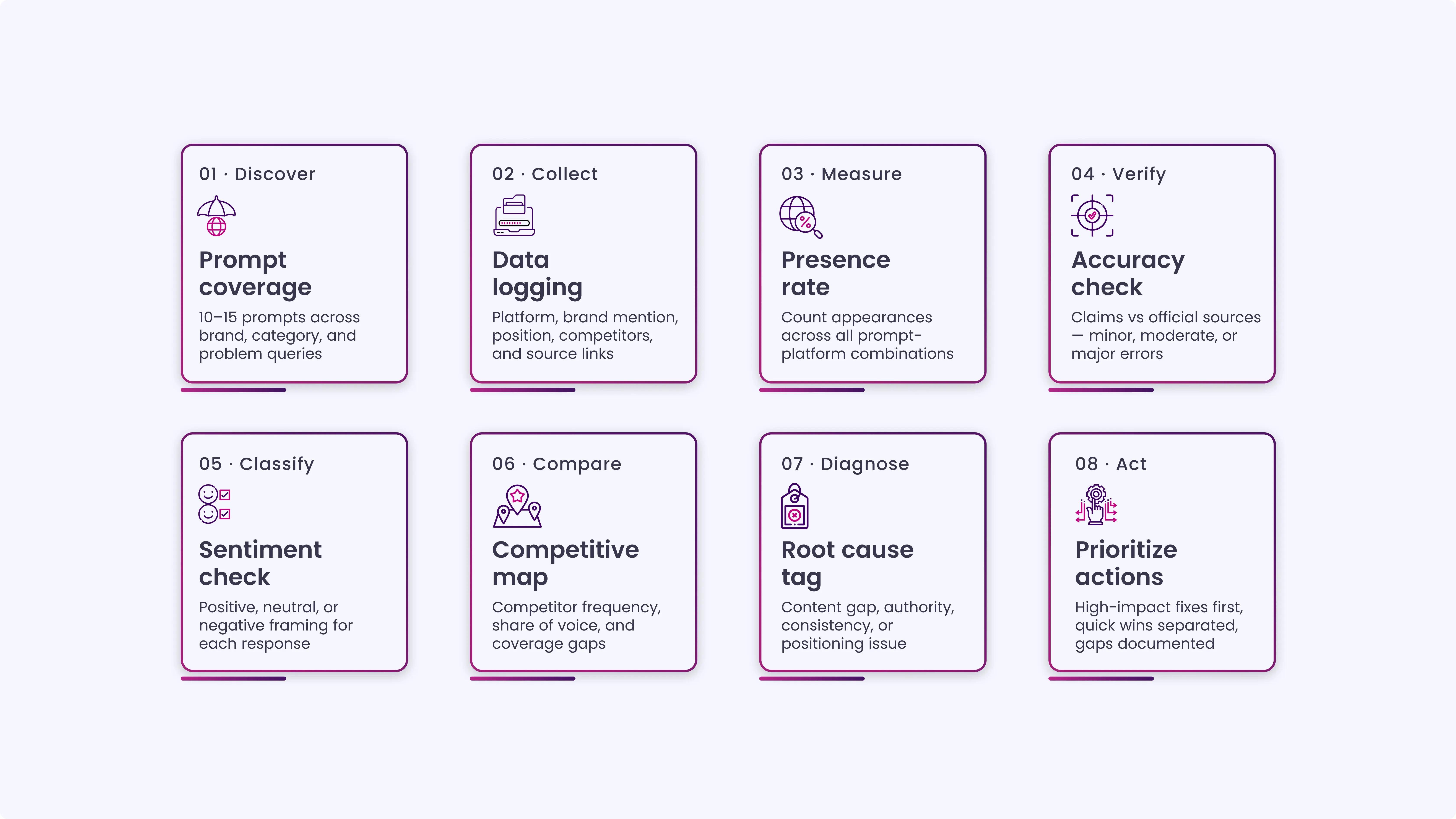
How to Run an LLM Brand Visibility Audit Step by Step
Before getting into the steps, here’s a quick view of how the LLM brand audit process works end to end:
Step 1: Build Your Prompt Set
The quality of an LLM audit depends entirely on the prompts you use. One prompt is not enough. You need a structured set that covers different entry points a real user might take.
Build prompts across three categories:
| Direct brand queries
“What is [Brand Name]?” “Tell me about [Brand Name], what do they do, who is it for, and what are the main strengths and weaknesses?” “Is [Brand Name] trustworthy? What do users say about it?” |
| Category and recommendation queries
“What are the best [category] tools for [use case]?” “Compare [Brand Name] vs [Competitor A] and [Competitor B].” “Which [category] platform would you recommend for a [company size] company in [industry]?” |
Run each prompt across ChatGPT, Perplexity, Claude, and Gemini. These four platforms dominate AI-driven discovery in 2026, and each handles source retrieval differently.
ChatGPT has the largest user base, Perplexity is growing fastest for research queries, Claude has strong enterprise adoption, and Gemini integrates with Google’s ecosystem. Covering all four gives you a complete picture.
Step 2: Document Everything in a Structured Log
Do not just read the responses and move on. Document every output systematically. Create a simple spreadsheet with these columns:
| Prompt | Platform | Brand mentioned? | Accuracy (Y/N/Partial) | Sentiment | Competitors mentioned | Source cited |
Fill this in for every prompt-platform combination. It takes time up front, but gives you a clean baseline you can compare against over 30, 60, and 90 days.
A few things worth noting as you document:
When your brand appears, note where it appears, first, second, third, or buried. Position matters. An LLM that mentions your brand fifth in a list of six is technically citing you, but it is not helping your consideration rate.
Note the exact language. If ChatGPT describes your product as “a good budget option” but you are positioned as a premium solution, that framing is a problem worth fixing.
Note what sources, if any, the LLM cites alongside your mention. Perplexity in particular surfaces source URLs. Those URLs tell you what content the model is pulling from when it talks about your brand.
Step 3: Assess the Four Dimensions
Once your log is complete, go through each dimension systematically:
Presence Audit
Count how often your brand appears across all prompts and platforms. Calculate a simple presence rate: appearances divided by total prompt-platform combinations.
If you ran 15 prompts across 4 platforms (60 combinations) and your brand appeared in 12 of them, your presence rate is 20%. That is your baseline.
AI Overviews now appear in approximately 48% of all Google searches, up from 34.5% in December 2025. Approximately 93% of AI Mode sessions end without a click, meaning brand visibility inside AI responses is often the only impression a user gets. A low presence rate is not just an inconvenience; it is a lost pipeline.
Accuracy Audit
Cross-check every factual claim in the responses against your official website. Common inaccuracies include: outdated product descriptions, wrong employee count or founding year, features attributed to your brand that belong to a competitor, pricing that is no longer current, and descriptions that reflect an old positioning your brand has moved away from.
Flag every inaccuracy. Categorize by severity: minor (easily ignored by a reader), moderate (creates confusion), or major (actively misleading).
Sentiment Audit
Read each response and classify the framing: positive, neutral, or negative. Then go a level deeper: what specific language is the model using? Words like “affordable,” “entry-level,” or “good for beginners” carry positioning implications. So do words like “enterprise-grade,” “widely trusted,” or “industry standard.”
If the sentiment does not match how you want your brand positioned, that is a signal about what content the LLM is drawing from.
Competitive Positioning Audit
For every category or recommendation prompt, note which competitors appear and how frequently. Calculate a simple share of voice: if your brand appears in 8 out of 20 recommendation responses and Competitor A appears in 16, their LLM share of voice is double yours. That gap is the competitive benchmark you are working to close.
Step 4: Identify the Root Causes
Most LLM visibility problems stem from one of three root causes.
Thin or absent web presence on specific topics. LLMs draw on publicly available information. If your brand has not published clear, authoritative content on a topic you want to be associated with, the model has nothing to work with. Absence of content = absence from the answer.
Inconsistent brand information across sources. LLMs generate inaccurate brand information when your website, press coverage, directory listings, and social profiles tell different stories.
If your LinkedIn says you were founded in 2016, your website says 2017, and a TechCrunch article from 2019 describes an earlier version of your product, the model reconciles these inconsistencies badly.
Weak third-party authority signals. LLMs weigh brands that appear in credible, independent sources more heavily than those that appear only on their own websites. Press mentions, analyst reports, credible review platforms, and editorial coverage all feed into how prominently a model surfaces your brand.
Step 5: Fix What You Find
Once you identify the root cause, the fix becomes clear and specific.
Presence Gaps
- Create content that directly answers the exact queries where your brand is missing
- Build dedicated pages for specific use cases (e.g., “best [category] tool for mid-market teams”)
- Avoid generic content, as it rarely gets cited by LLMs
Accuracy Problems
- Audit your website, Google Business Profile, LinkedIn, and major directories
- Ensure all brand information is consistent and up to date
- Add Organization schema markup on your homepage to give LLMs a structured source
- Fix outdated third-party content by updating listings or reaching out to publishers
Sentiment Issues
- Publish content that reshapes how your brand is described over time
- Use case studies, deep-dive technical content, and third-party validation
- Align content with the positioning you want (e.g., enterprise vs budget perception)
- Expect 4-8 weeks for LLM responses to reflect these changes
Competitive Gaps
- Analyze where competitors are being mentioned more frequently
- Check analyst reports, comparison pages, and industry roundups
- Identify topics where competitors have stronger visibility than you do
- Invest in those content and authority gaps across external platforms
Step 6: Set Up Ongoing Monitoring
A one-time audit gives you a snapshot. Ongoing monitoring turns it into a system.
Manual Tracking (Minimum Setup)
- Run your core prompt set once a month
- Update your tracking log consistently
- Monitor your presence rate over time
- Flag any new inaccuracies as they appear
Automation Tools (Scale Option)
If you want to automate tracking, several tools now support LLM visibility monitoring:
- Peec AI: Tracks ChatGPT, Perplexity, and Google AI Overviews with structured reporting
- Scrunch AI: Focuses on narrative control and fixing misinformation in AI-generated answers
- AthenaHQ: Provides sentiment tracking, gap analysis, and multi-LLM brand health insights across ChatGPT, Gemini, Claude, and Perplexity
Most tools typically range between $30-$200/month, depending on usage and coverage.
Free Entry Option
- Otterly.AI: Entry-level monitoring for Google AI Overviews, ChatGPT, Gemini, and Perplexity
- Used by 20,000+ marketing professionals
- Suitable for teams starting out with basic tracking needs
Review Timing
- Run a quarterly deep review of all insights
- Track changes in visibility, sentiment, and competitor presence
- Reassess content impact and new competitors entering the space
AI platforms evolve quickly, competitors shift frequently, and your content takes time to reflect in outputs, so a quarterly review is the minimum baseline for staying accurate and relevant.
Turn Visibility Into Consistent AI Presence
Running the audit is only step one. The brands that consistently appear in LLM responses share a few core traits.
They publish content that directly and specifically answers buyer questions, not broad awareness content, but precise, intent-driven answers tied to real use cases in their category.
They maintain consistency across every public touchpoint; their website, schema markup, directories, and press coverage all tell the same story. They earn credibility through independent sources, editorial mentions, analyst coverage, review platforms, and community citations, not just their own content.
They update regularly, keeping information fresh so it flows into AI systems that rely on continuously indexed data rather than static snapshots.
None of these is a quick fix. They are compounding signals. An audit without action is just documentation. The real value comes from turning insights into focused, repeatable improvements that strengthen visibility over time.
Common LLM Audit Failure Patterns (Diagnostic Layer)
Most LLM visibility issues don’t appear randomly. They follow repeatable patterns that show up across prompts, platforms, and categories. Identifying the pattern is what helps you fix the right problem instead of guessing.
Invisible But Established
Your brand exists in the market but does not appear in LLM responses.
This is usually not a reputation problem. It is a visibility gap inside AI retrieval systems.
What this looks like in practice is simple. People in your industry may know your brand, but LLMs never surface it when users ask category-level questions or comparisons.
Misaligned Positioning
The model describes your brand differently from how you actually position it.
This shows up when there is a gap between your intended messaging and the language available online.
You may see consistent framing that does not align with your current positioning, especially around pricing tiers, audience levels, or product maturity.
Competitor Dominance Effect
Competitors consistently appear in answers where your brand is relevant but missing.
This is not about product quality. It is about the distribution of information across the web.
In most cases, the model has more exposure to competitor mentions across trusted sources than to your brand.
Fragmented Brand Signals
The model pulls inconsistent or incomplete information about your brand.
Instead of one clear narrative, different sources describe your brand differently.
This creates unstable outputs across platforms, where details change depending on which source the model retrieves.
Low Influence Mentioning
Your brand is mentioned, but it does not influence the final recommendation.
You appear in responses but are not framed as a strong option. In most cases, this is a positioning strength issue inside the model’s ranking logic rather than an absence.
LLM Visibility Audit Checklist (Operational SOP)
Use this as a single execution sheet every time you run an audit. Run across all four platforms: ChatGPT, Perplexity, Claude, and Gemini.
INSIDEA
Ready to get found by people and AI?
Search and answer-engine visibility that compounds, built to be cited.


