The llms.txt standard appeared in September 2024 as a lightweight way for websites to describe their structure to large language models during content retrieval.
It uses a simple Markdown format to list important pages, explain what each page covers, and show how content is organized. Unlike robots.txt or sitemap.xml, which focus on access rules and URL listing, this format focuses on explaining content.
Adoption is still uneven. A few AI tools and crawlers have shown early or partial support, but there is no shared implementation across major systems, and it is not a formal standard.
Even so, adding it requires minimal effort and introduces no risk for sites that want a clear, machine-readable structure.
This blog explains five common llms.txt mistakes that reduce interpretive clarity and what needs to be corrected in each case.
5 llms.txt Issues That Distort AI Interpretation of Your Content
Most llms.txt setups fail in predictable ways. Here’s what usually goes wrong:
1. Absence of llms.txt File
| Impact level: High
Content structure is completely unguided for systems that support the file |
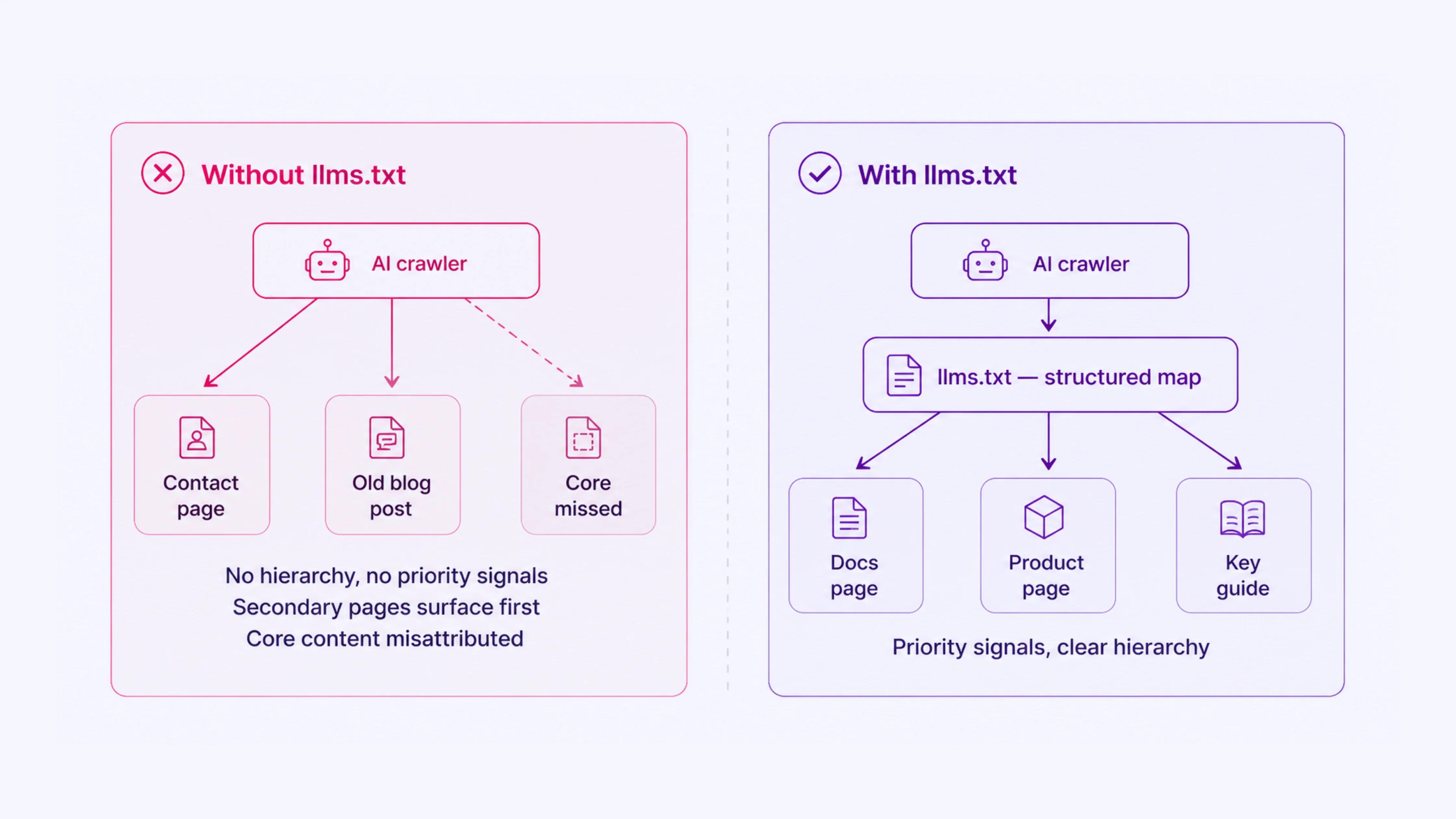
When no llms.txt file exists, AI systems that look for one fall back to independent page parsing with no hierarchy, no priority signals, and no summary context.
The result is often a fragmented picture of the site, with secondary pages surfacing instead of primary ones, or with content misattributed simply because nothing indicates its purpose.
robots.txt controls crawler access. sitemap.xml lists URLs. Neither tells an AI system what a page is about, how it fits into the broader site, or which pages represent core content. llms.txt fills that gap for systems that consume it.
Use Case:
- Beginner: Unaware that the file exists and assumes the existing SEO configuration covers AI crawlers.
- Intermediate: Has a complete sitemap and robots.txt setup but treats those as sufficient for AI retrieval.
- Advanced: Deploys through a CI/CD pipeline that was never configured to include or generate llms.txt, so the file is silently excluded from production builds.
What to do:
- Create llms.txt at your root: yourdomain.com/llms.txt
- Use the standard Markdown format: H1 site name, a blockquote summary, and H2 sections with annotated links
- Add an llms-full.txt file if your site has substantial content that benefits from direct ingestion
The effect depends on whether the AI system actually reads llms.txt during retrieval. This improves structure, not certainty about ranking.
2. Restricted Access to High-Value Pages
| Impact level: High
Content becomes inaccessible or incomplete for retrieval |
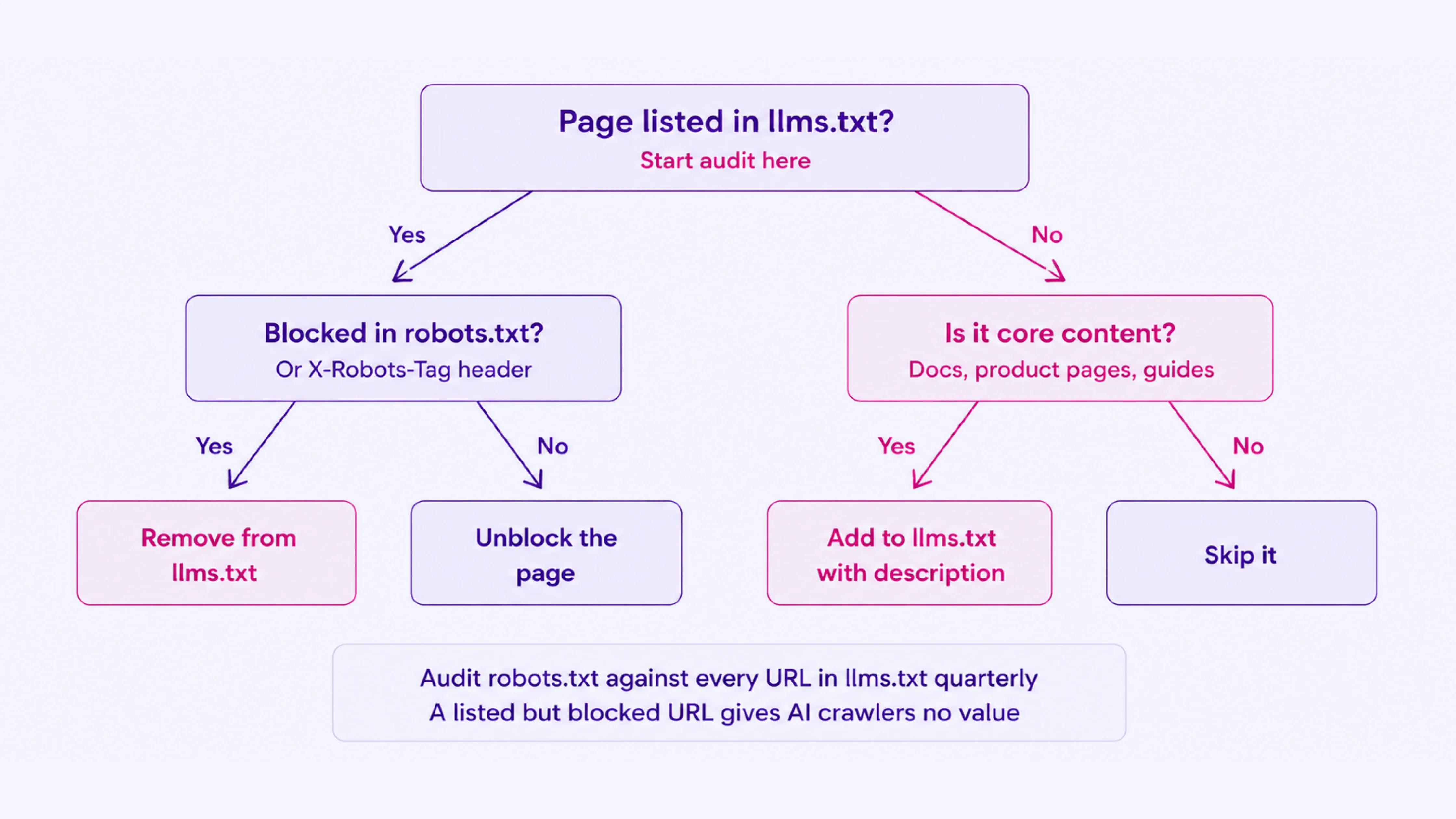
Some sites use robots.txt directives or X-Robots-Tag headers to block AI user agents, then list those same pages in llms.txt.
This contradiction means that even where a system reads the file and tries to retrieve the linked content, it hits an access block. The page goes unread regardless of how well it is described.
A related issue: some site owners intentionally exclude their best content from AI retrieval, assuming that if AI tools summarize it, users will not click through. This logic ignores how AI-assisted search tools work. Most cite sources and surface them to users. If the content is inaccessible, it does not get cited.
Common AI crawler user agents include GPTBot, ClaudeBot, PerplexityBot, and Google-Extended. Blocking behavior varies across these systems and is not uniformly enforced, but when blocks are respected, inaccessible pages lead to an incomplete understanding of content.
Use Case:
- Beginner: Copies a blanket AI-blocking directive from a forum post without reviewing which pages it affects.
- Intermediate: Blocks AI crawlers site-wide for content protection reasons but still adds pages to llms.txt, hoping some systems will read descriptions without fetching content.
- Advanced: Has granular blocking rules per subdirectory, but a recent site restructure moved cornerstone content into a blocked path without anyone noticing.
What to do:
- Audit your robots.txt against the pages listed in llms.txt
- Remove blocks on pages you want AI systems to retrieve, or remove those pages from llms.txt if the block is deliberate
- Keep both files consistent. A link in llms.txt pointing to a blocked URL provides no interpretive value
Impact varies across systems. Some AI crawlers do not fully respect robots.txt directives. Behavior is not standardized.
3. Poor Page Descriptions in llms.txt
| Impact level: Medium
Content misclassification risk in systems that process descriptions |
Every link in llms.txt supports a short description field. In many implementations, this field is left blank or filled with generic labels like “Product page” or “Blog post.”
In systems that use these descriptions to build a semantic map of your site, generic labels provide almost no useful signal.
Inaccurate descriptions are a separate problem. If a description says a page covers one topic, but the actual content covers another, AI systems that rely on the description for retrieval decisions draw the wrong inferences.
Over time, that inaccuracy compounds as the model’s internal representation of the site drifts further from reality.
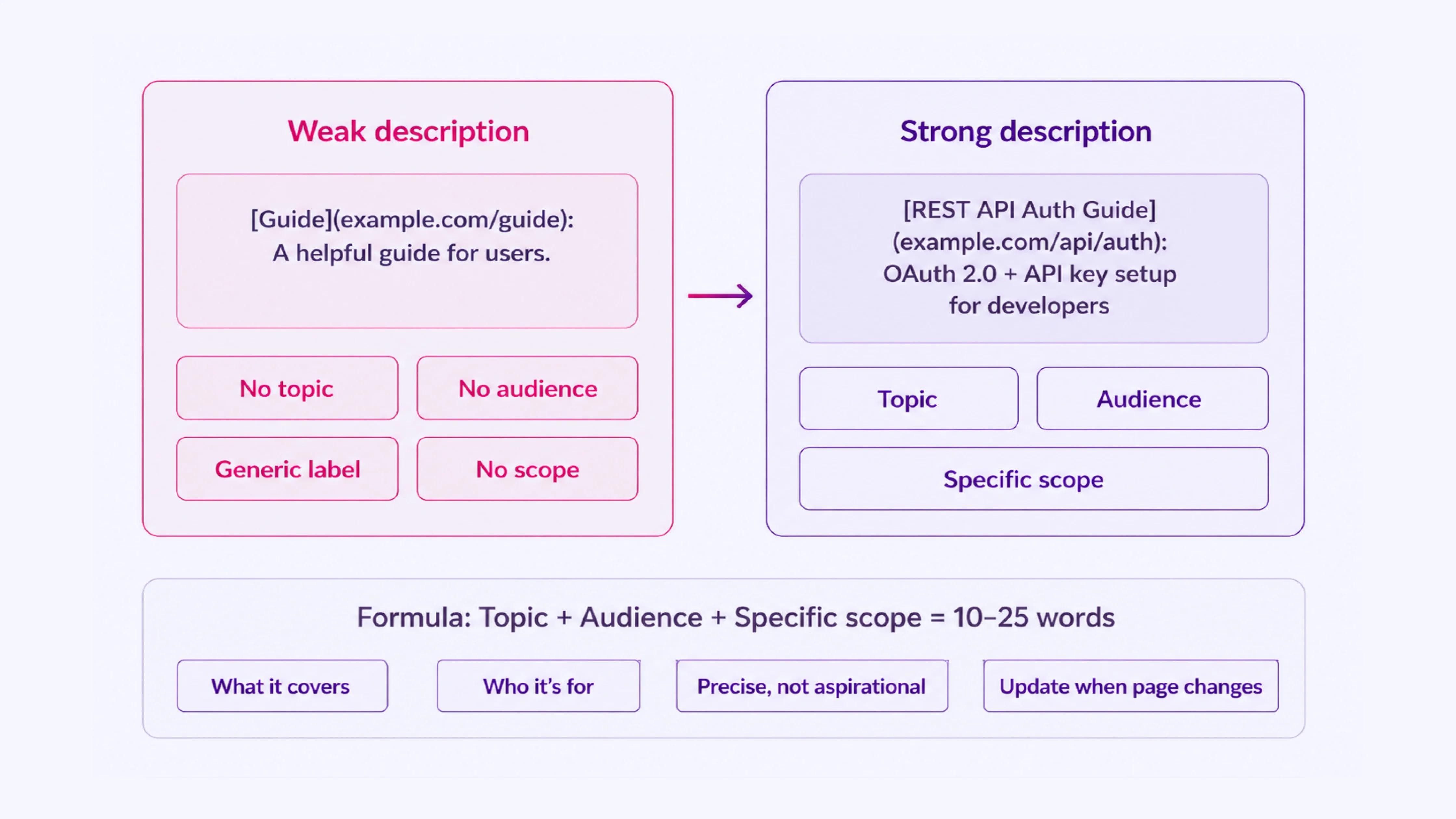
Weak description:
- [Guide](https://example.com/guide): A helpful guide for users.
Stronger description:
- [REST API Authentication Guide](https://example.com/api/auth-guide): Step-by-step OAuth 2.0 and API key setup for developers integrating with the platform.
Use Case:
- Beginner: Copies page titles directly as descriptions with no additional context.
- Intermediate: Writes keyword-heavy descriptions that do not accurately reflect page content.
- Advanced: Has product documentation spread across dozens of pages with inconsistent semantic labeling, causing AI systems to conflate separate topics.
What to do:
- Write descriptions that include the topic, audience, and specific scope of the page
- Keep descriptions between 10 and 25 words
- Use precise language that reflects actual content, not aspirational framing
- Update descriptions when the underlying page changes substantially
This improves structure and interpretability. Whether a specific AI system uses descriptions for retrieval weighting is not standardized.
4. Outdated llms-full.txt Content
| Impact level: Medium Limits the depth of content available for direct ingestion where supported |
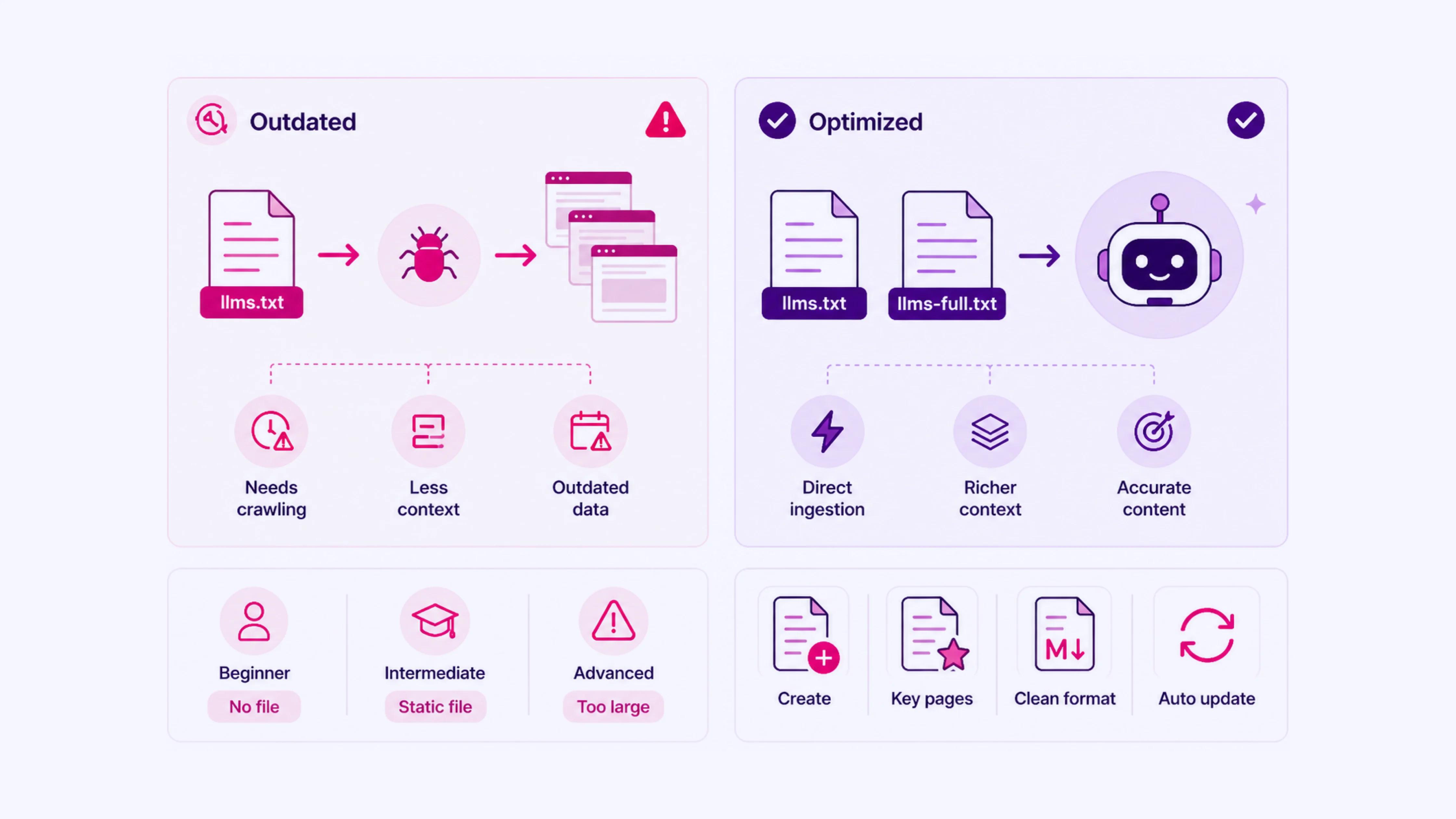
The llms.txt standard includes a companion file: llms-full.txt. Where llms.txt provides an index of links with descriptions, llms-full.txt includes the actual page content, formatted for direct AI ingestion.
For systems that support it, this reduces the need to crawl individual URLs and gives the model a richer context to work with.
Most sites either skip the file entirely or create it once and leave it static. Both reduce its usefulness.
A static llms-full.txt file that has not been updated since launch reflects outdated content, creating mismatches between what the file says and what the live site actually contains.
For documentation platforms, research blogs, and technical knowledge bases, llms-full.txt can improve retrieval accuracy in systems that read it by providing complete, well-formatted content rather than partial page scrapes.
Use Case:
- Beginner: Has never heard of llms-full.txt and assumes llms.txt alone is sufficient.
- Intermediate: Creates llms-full.txt during initial setup but never builds an update process into the content workflow.
- Advanced: Includes all pages in llms-full.txt without curating priority content, making the file excessively large and reducing the relative weight of important pages in systems that process it.
What to do:
- Create llms-full.txt at the root level alongside llms.txt
- Include full-text content for cornerstone pages: documentation, primary product explainers, high-value editorial content
- Format content using clean Markdown headers and paragraphs
- Build a regeneration process into your CMS or static site generator so the file updates when core content changes
The effect is limited to AI systems that explicitly support ingestion of llms-full.txt. Support is partial and not universal.
5. Treating llms.txt as a One-Time Setup
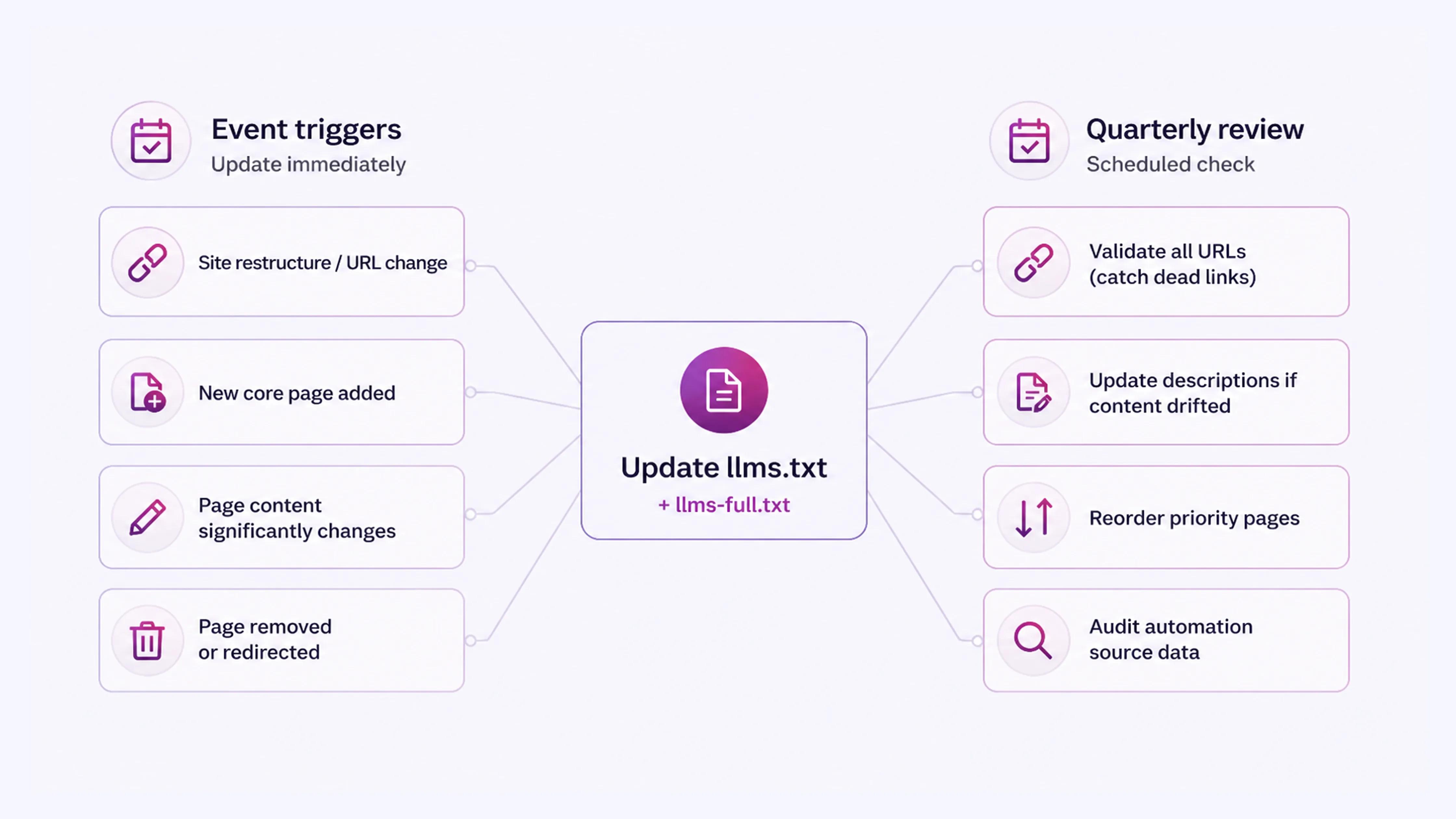
| Impact level: Medium
Interpretive accuracy degrades as the file becomes outdated |
llms.txt is configured once and left alone, loses relevance as the site changes. New pages go unlisted. Removed pages remain in the file as broken links.
Sections that were secondary at launch become central to the site’s content strategy but still appear low in the file with outdated descriptions.
For AI systems that periodically re-read the file, a stale llms.txt creates a growing gap between the structured interpretation it provides and the actual content on the site.
Broken link entries are particularly problematic: in systems that attempt to retrieve listed URLs, dead links reduce successful content retrieval without flagging an obvious error.
Link ordering in llms.txt is primarily useful for human readability and may influence parser heuristics in some implementations. There is no confirmed evidence that ordering affects retrieval weight across AI systems, but keeping the most important content listed prominently is a reasonable practice for both human editors and potential parser logic.
Use Case:
- Beginner: Sets up the file during a site launch sprint and never returns to it.
- Intermediate: Updates the file when major pages are added, but misses incremental changes such as page migrations, URL restructures, or content consolidation.
- Advanced: Automates llms.txt generation through a build script, but the automation pulls from a page list that is itself outdated, so the generated output reflects the site’s old architecture.
What to do:
- Review llms.txt and llms-full.txt on a quarterly basis
- Treat site restructures and significant content additions as triggers for an immediate update
- Validate all URLs in the file regularly to catch dead links before they accumulate
- If using automated generation, audit the source data the automation pulls from, not just the output file
This improves structural accuracy over time. Impact on any specific AI system’s retrieval behavior depends on that system’s support for the standard.
What Improves After Fixing llms.txt Errors
llms.txt is a structured interpretation hint, not a ranking mechanism. It gives AI systems that support it a clearer way to read your site: what exists, where to find it, and what each section covers.
The five mistakes covered here all reduce that clarity in different ways. Some make content inaccessible. Some cause misclassification. Some let the file go stale until it no longer reflects the site it is supposed to describe.
Fixing these issues is a configuration and maintenance task, not a technical overhaul. The realistic expectation is better AI content interpretation, where supported, with benefits that scale as adoption across AI systems grows.
Build llms.txt the Right Way for AI Systems with INSIDEA

llms.txt is a structured layer that influences how AI systems interpret your website, map your content, and decide what to retrieve.
Most setups fail at consistency. Pages are listed without alignment, descriptions stay vague, and access rules conflict with what is declared in the file. This leads to fragmented or incorrect interpretation.
INSIDEA helps bring structure, clarity, and maintenance discipline to your llms.txt setup so your llms.txt reflects your actual site architecture and supports accurate AI retrieval.
Here is how we help:
- llms.txt Structure Design: We build a clean, hierarchical layout of your content so AI systems can clearly distinguish core pages, supporting pages, and reference material.
- Content Mapping & Description Alignment: We align every listed URL with accurate, intent-based descriptions so that AI systems interpret pages correctly rather than relying on generic labels.
- Access Consistency Audit: We identify conflicts between llms.txt entries and robots or header-level restrictions, ensuring listed content is actually accessible for retrieval.
- llms-full.txt Configuration: We define what deserves full-content inclusion and structure it so AI systems that support deeper ingestion receive complete, usable context.
- Ongoing Update Framework: We set up a lightweight maintenance flow to keep your llms.txt aligned with new pages, removals, and structural changes without drift over time.


