Most people still associate search with typing. You write a query, you get a list of links. That habit is changing, and most brands are yet to adapt.
Over 36% of online consumers had already used visual search, and adoption has grown steadily since, particularly among mobile-first users and younger audiences. Google Lens alone now processes billions of queries every month.
People are pointing cameras at products they want to buy, dishes they want to order, plants they can’t identify, and storefronts they’re standing in front of, and getting instant, useful answers back.
What looks effortless on the surface is built on a sophisticated stack of AI technology. And underneath that technology sits a real commercial opportunity, or a real visibility gap, depending on whether your brand has paid attention to it yet.
This blog walks through both: how AI visual search actually works, and what it means in practice for discovery, discoverability, and brand presence.
Two Approaches to Visual Search

Visual search can work in two main ways. One approach relies on image metadata, tags that describe the image’s category, color, shape, and other attributes. The system then uses these tags to return relevant results, still leaning on text-based search behind the scenes.
The second approach uses the image itself as the query. Advanced AI algorithms analyze visual features such as shape, color, texture, and subtle patterns, sometimes even surpassing human perception. This is how reverse image search and semantic visual search deliver precise, meaningful matches.
Both methods have their place, and modern platforms often combine them to give faster, more accurate results while making it easy for users to find exactly what they’re looking for.
The Technology Behind AI Visual Search
Before we get into how visual search actually works, let’s take a moment to see what happens when you snap or upload an image. Every photo you share is analyzed for objects, text, and context, so the system can give you results that actually make sense.
| Here is what happens, in sequence:
Every section below is an in-depth look at one of these steps. |
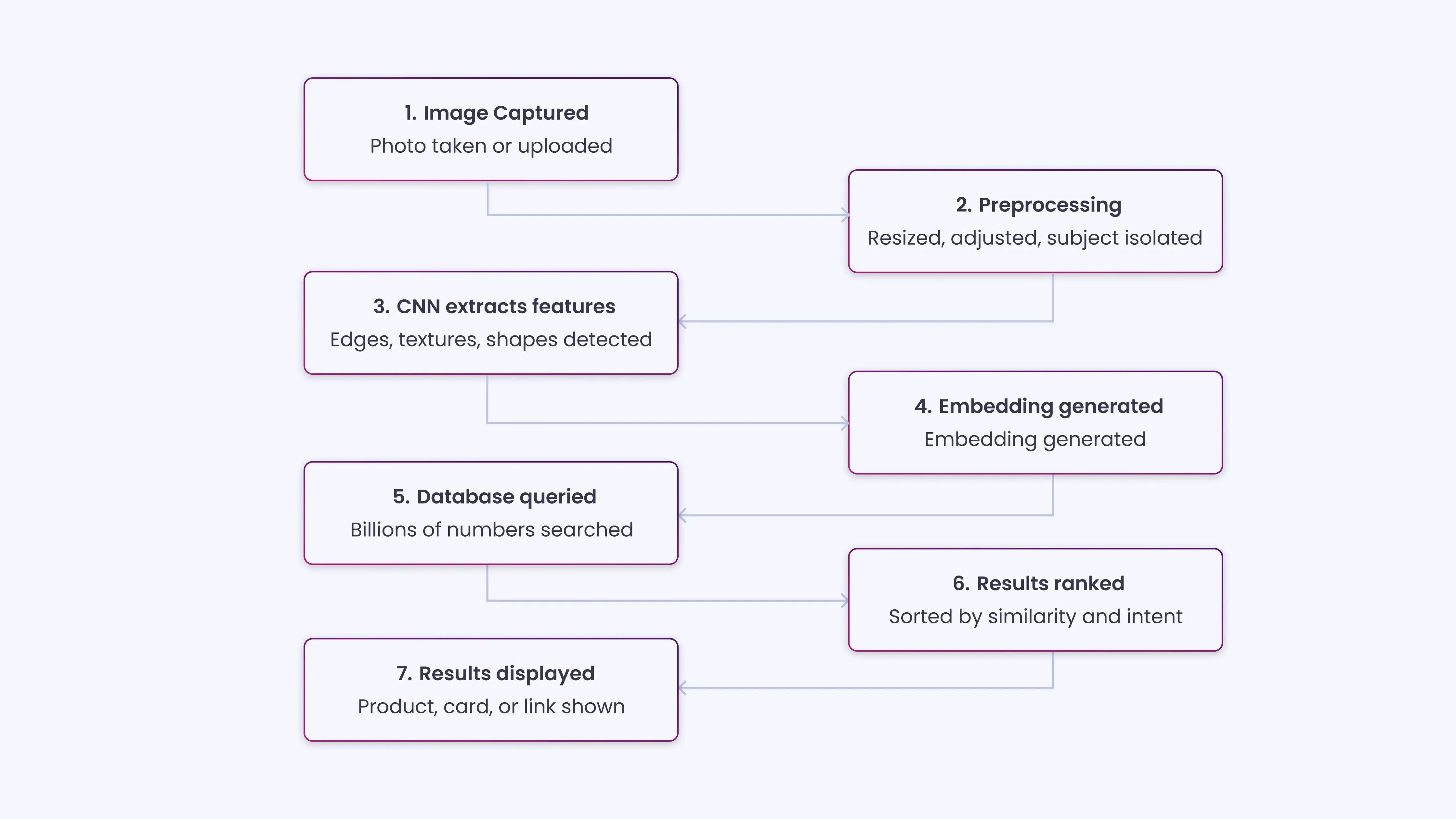
For brands, knowing this process shows exactly where you can appear, get noticed, and connect with the right audience at the right moment.
Image Input and Preprocessing
Everything starts with the image itself. When a user uploads a photo or activates a camera-based search, the system receives raw image data and prepares it for analysis.
At this stage, the system handles:
- Image size normalization
- Lighting and contrast adjustments
- Format conversion for processing
Critically, this stage also involves segmentation, isolating the primary subject from the background.
If someone photographs a sneaker on a cluttered shelf, the system needs to separate the sneaker from the rest of the clutter before it can analyze it meaningfully.
More advanced systems handle this automatically, without the user having to crop or adjust anything.
Feature Extraction Through Convolutional Neural Networks
Once the image is preprocessed, the core analysis begins. Most AI visual search systems use a class of deep learning architecture called a Convolutional Neural Network, or CNN.
CNNs process images in layers:
- Early layers detect edges, corners, and color gradients
- Deeper layers identify textures, shapes, and object parts
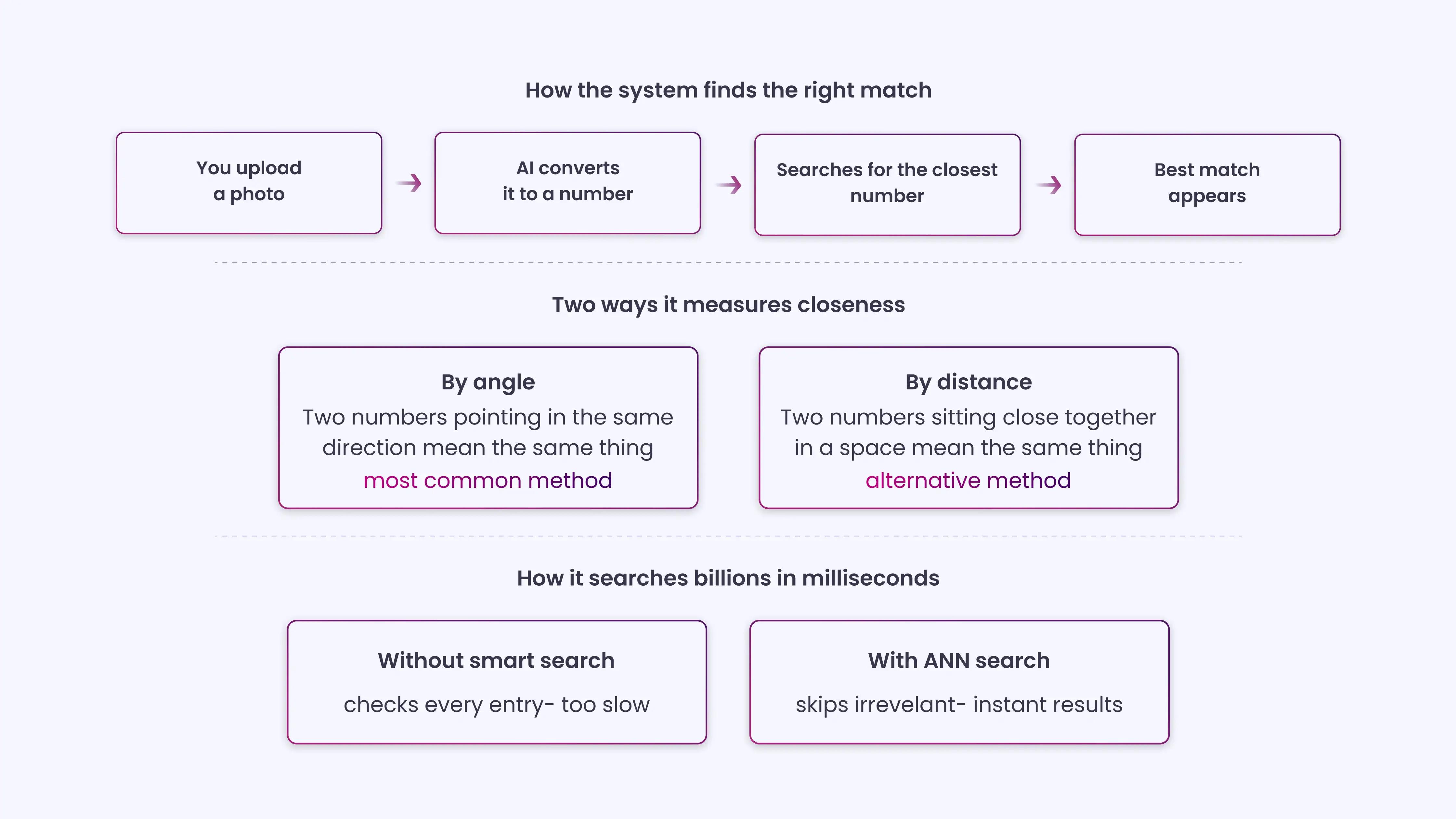
The final layers synthesize all of this into a high-dimensional numerical vector called an embedding, which represents the image’s visual characteristics in a format a computer can compare against.
Every image processed by the system gets its own embedding. Visually similar images produce embeddings that are numerically close. When a user submits a photo, the system generates an embedding for it and searches its database for the closest matches.
This is how visual similarity gets translated into search results.
Not all CNNs are built the same. Platforms use different architectures depending on their accuracy and speed requirements:
Most major platforms don’t build these models from scratch. They use transfer learning, starting with a model pre-trained on hundreds of millions of images and fine-tuning it on their own dataset. This dramatically reduces training time while preserving accuracy. Training data volume also directly shapes the quality of results. A model trained on 1 billion labeled images will recognize niche objects, uncommon angles, and culturally diverse subjects far more reliably than one trained on 10 million. |
| What is an Embedding?
An embedding is a numerical representation of an image’s visual features. It captures patterns, shapes, colors, and textures in a format the system can compare with millions of other images. Images that look or mean the same produce embeddings that are close together, enabling AI visual search to identify matches quickly and accurately. Embeddings are typically 512- or 2048-dimensional. Each number represents a learned visual characteristic. Two images of the same sneaker from different angles will produce embeddings that are numerically very close. Two completely different objects will produce embeddings that are far apart. |
Object Recognition and Classification
Alongside feature extraction, the system also performs object recognition. It learns from millions of images that have already been labeled by humans, so it can understand what’s in each photo
Through this training, the model learns to assign category labels to what it sees:
- Chair
- Espresso machine
- Golden retriever
- Leather handbag
- Floor lamp
This classification layer is what separates modern AI visual search from simple image matching.
If you photograph a specific sofa style, the system doesn’t just return similar photos; it understands it’s a sofa, applies category logic, and can filter results by retailer, price range, or style.
The classification step turns pixel data into semantic meaning.
Reverse Image Search vs. Semantic Visual Search
These two modes often get grouped together, but they work differently and serve different purposes.
Reverse image search:
- Matches a submitted image against indexed copies
- Finds duplicates or near-identical images
- Helps identify original sources or reuse
Semantic visual search:
- Understands what’s in the image
- Retrieves results based on meaning, not duplication
When you photograph a houseplant using Google Lens, it doesn’t search for identical photos. It identifies the species, retrieves care information, and may suggest where to purchase one.
The shift from pixel-matching to meaning-extraction defines modern visual search.
Multimodal AI Combining Images and Text
The most significant recent development in AI visual search is multimodal processing, systems that handle images and text in a single query. GPT-4o, Google Gemini, and Claude all accept image inputs alongside text prompts.
A user can upload a photo and ask:
- “What’s the name of this architectural style?”
- “Find me a similar jacket in navy.”
- “Is this plant safe for cats?”
The AI doesn’t just identify the image; it reasons about it and returns a response aligned with the user’s intent. Pure visual matching tells you what something is. Multimodal AI tells you what to do next.
| What makes multimodal systems fundamentally different is their underlying architecture. Most are built on a framework called CLIP (Contrastive Language-Image Pretraining), developed by OpenAI.
Here is how CLIP works:
The result is a system that can match visual input to language intent, not just visual input to other visual input. Cross-attention further strengthens this. When a user uploads a photo and asks a question, the model distributes its focus across different regions of the image based on the text query. A question about color directs attention to surface and texture regions. A question about brand directs attention to logos or labels. This is why multimodal visual search feels more like reasoning than matching. |
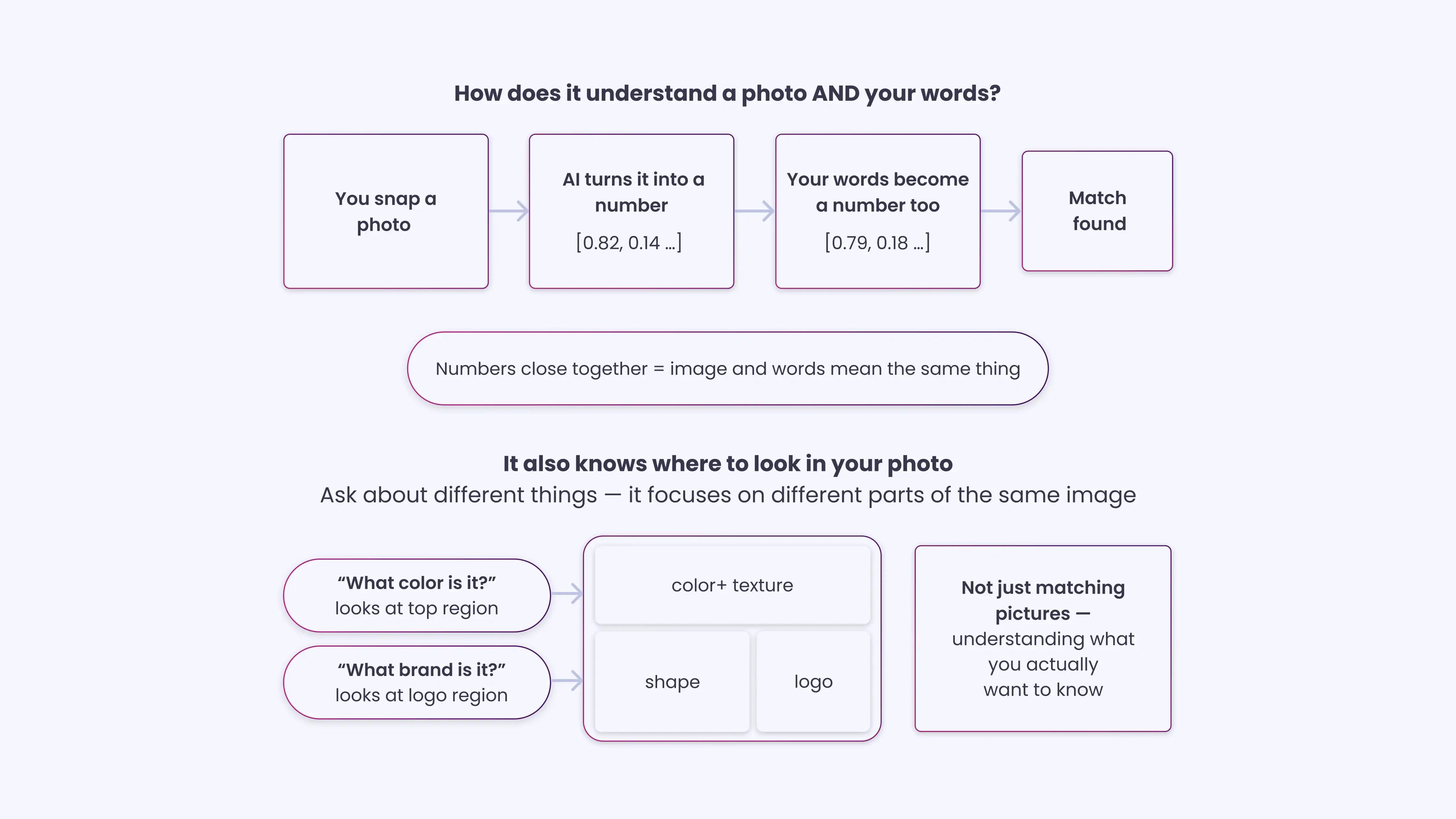
Text Within Images With OCR
A large part of what makes tools like Google Lens useful is their ability to read text in images.
This includes:
- Restaurant menus
- Street signs
- Business cards
- Book covers
- Product labels
- Receipts
This is handled through Optical Character Recognition, or OCR, integrated into the visual search pipeline. When a user photographs a menu written in another language, the system extracts the text, translates it, and returns a readable result. This happens in seconds, without the user typing anything.
The combination of visual recognition and text extraction makes visual search useful in real-world situations where text search falls short.
Vector Databases that Deliver Immediate Results
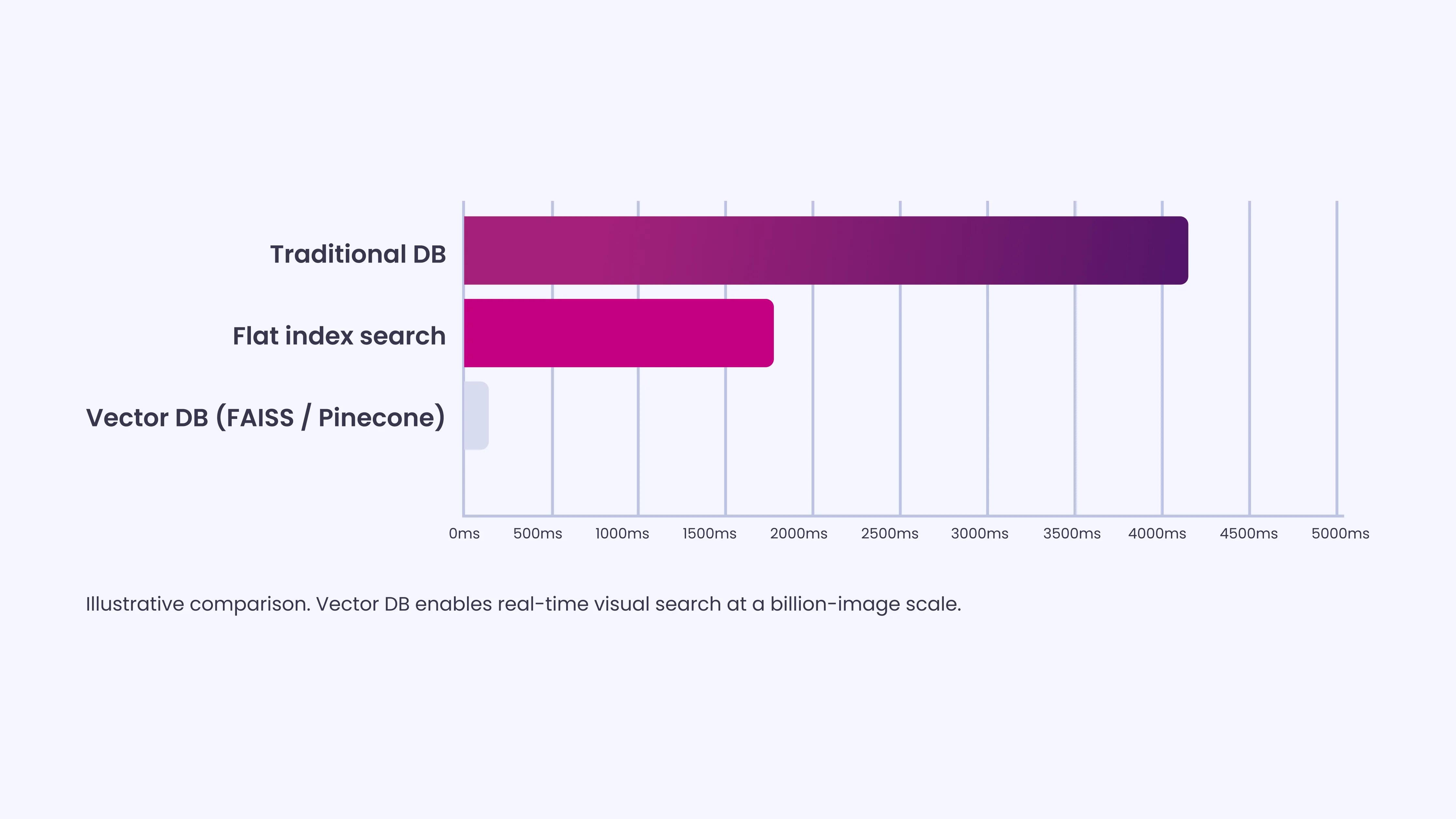
After an image converts into an embedding, the system needs to find the closest matches across massive datasets.
These databases often contain:
- Hundreds of millions
- Or billions of indexed images
Vector databases make this possible.
Unlike traditional databases that retrieve exact matches, vector databases find results that are numerically close to the query embedding.
This corresponds to images that are visually or semantically similar.
Infrastructure such as Meta’s FAISS and platforms such as Pinecone support this process at scale.
The speed of vector search allows visual search to feel instant. Without it, retrieving results across massive datasets would take far too long.
How AI Visual Search Connects People and Brands?
AI visual search is becoming part of everyday experiences. People use it to identify, compare, and explore the world around them. For brands, recognizing where it appears highlights opportunities to capture attention and influence decisions at the moment of discovery.
How Major Platforms Use Visual Search
Here’s how the major platforms turn images into actionable results
- Google Lens: Processes billions of queries per month across object detection, translation, product discovery, and more.
- Pinterest Lens: Focuses on product and style discovery with strong purchase intent.
- Amazon visual search: Lets users photograph products and find similar items directly within the app.
- Bing Visual Search: Connects visual input with AI-generated responses in Copilot.
- Instagram and Snapchat: Use visual AI for product tagging, AR filters, and in-app shopping experiences.
How Visual Search Drives Product Discovery
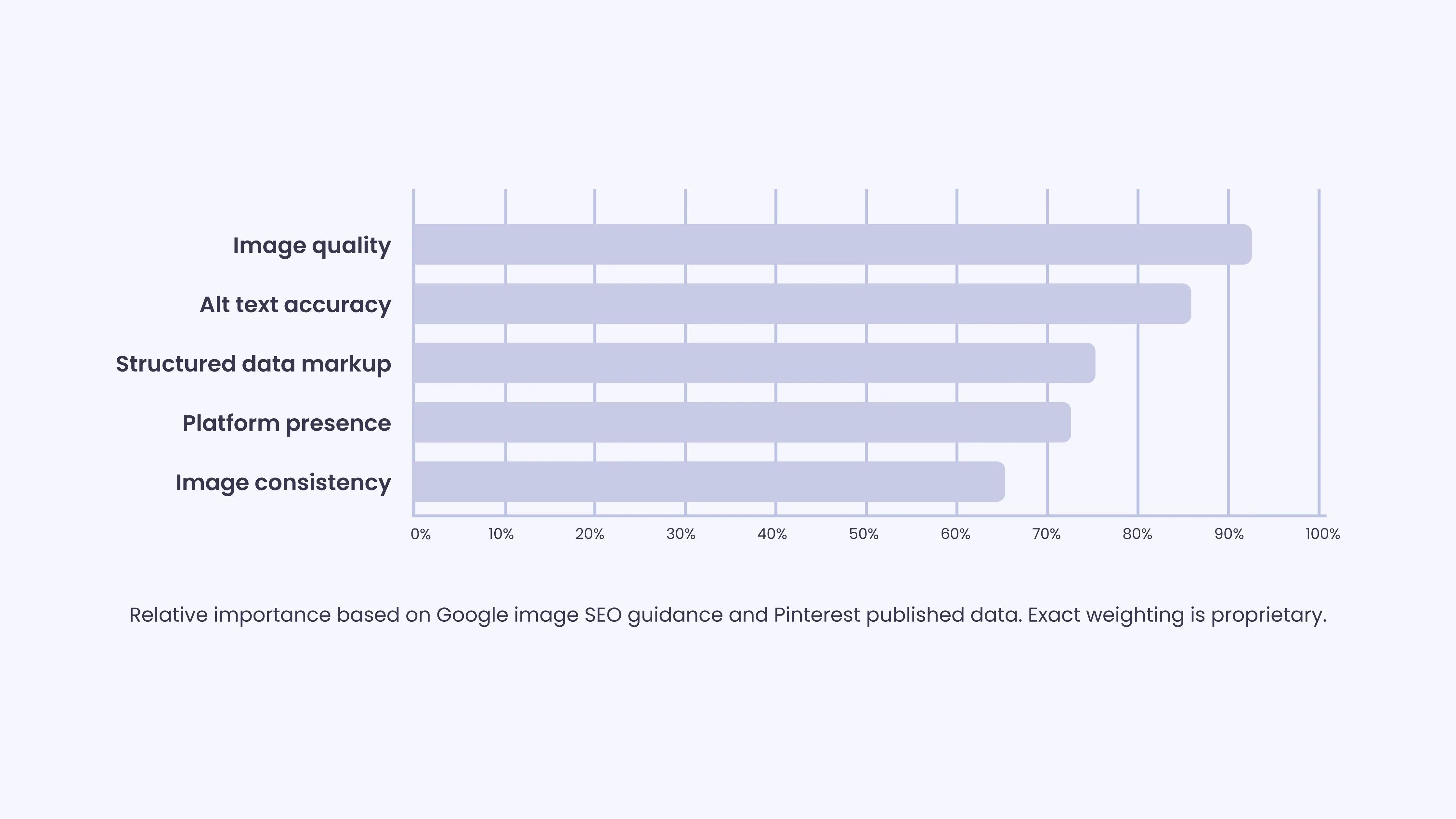
For e-commerce brands, visual search is a distinct and growing traffic source. When a user photographs a product, the AI returns visually and categorically similar results.
Visibility depends on:
- Image quality
- Structure and optimization
- Metadata and context
Google’s image SEO guidance reflects this shift. File names, alt text, page context, image resolution, and structured data all influence how products appear.
Pinterest data shows that shoppable pins with rich metadata outperform unoptimized images.
For visually driven categories, this is a measurable acquisition channel.
How Visual Search Supports Local Discovery
Visual search also plays a role in local discovery.
When users photograph:
- Storefronts
- Food
- Buildings
Tools like Google Lens return:
- Business details
- Reviews
- Directions
- Menus
For local businesses, visibility depends on:
- Image quality
- Accurate location data
- Strong photo coverage
Low-quality visuals reduce visibility at the moment of intent.
Limitations of the AI Visual Search
AI visual search has real limitations that brands and users should be aware of:
Accuracy challenges
- Struggles with niche or highly specialized subjects
- Performs inconsistently in underrepresented regions
Privacy concerns
- Facial recognition raises ethical and legal issues
- Major platforms restrict face-based identification
Bias in results
- Skewed representation in outputs
- Misclassification across different cultural contexts
These limitations affect both user trust and your brand’s visibility in search-driven discovery.
The Future of Visual Search for Brands
Visual input is becoming a primary way people search. Wearable AI devices, like Meta’s smart glasses and early products from Humane, rely on camera-based interaction. Multimodal AI continues to evolve, moving from simple object identification to reasoning, understanding context, value, and use.
For brands, this is clear: visual content is more than branding, it’s a search surface that drives visibility. High-quality images, structured metadata, and clear content now directly impact how AI systems represent your brand.
Companies that treat visual content as a strategic asset will secure durable visibility, while those that haven’t yet will risk falling behind.
INSIDEA
Ready to get found by people and AI?
Search and answer-engine visibility that compounds, built to be cited.


